How Cameras and Eyes See Light: From Spectra to Illuminants
Light is never just “white.” It has a shape, a fingerprint, a dance across wavelengths. Cameras record it, eyes interpret it, and both struggle in their own ways. In this post, we’ll walk step by step through the chain: spectral power distribution, surface reflectance, camera sensitivity, illuminant estimation, and the knotty problem of multiple light sources.
Table of Contents
- Spectral Power Distribution: The Fingerprint of Light
- Surface Reflectance: How Materials Shape Light
- Camera Spectral Sensitivity: What Sensors Respond To
- Why Multiplication?
- From Cones to Debayering
- Illuminant Estimation: Guessing the Light Source
- The Gray World Assumption
- Minkowski Norm Estimates: A Family of Fixes
- Coping with Limitations
- Multiple Illuminants: The Real Mess
- How Humans Do It: The Goal of Color Constancy
- Closing Thoughts
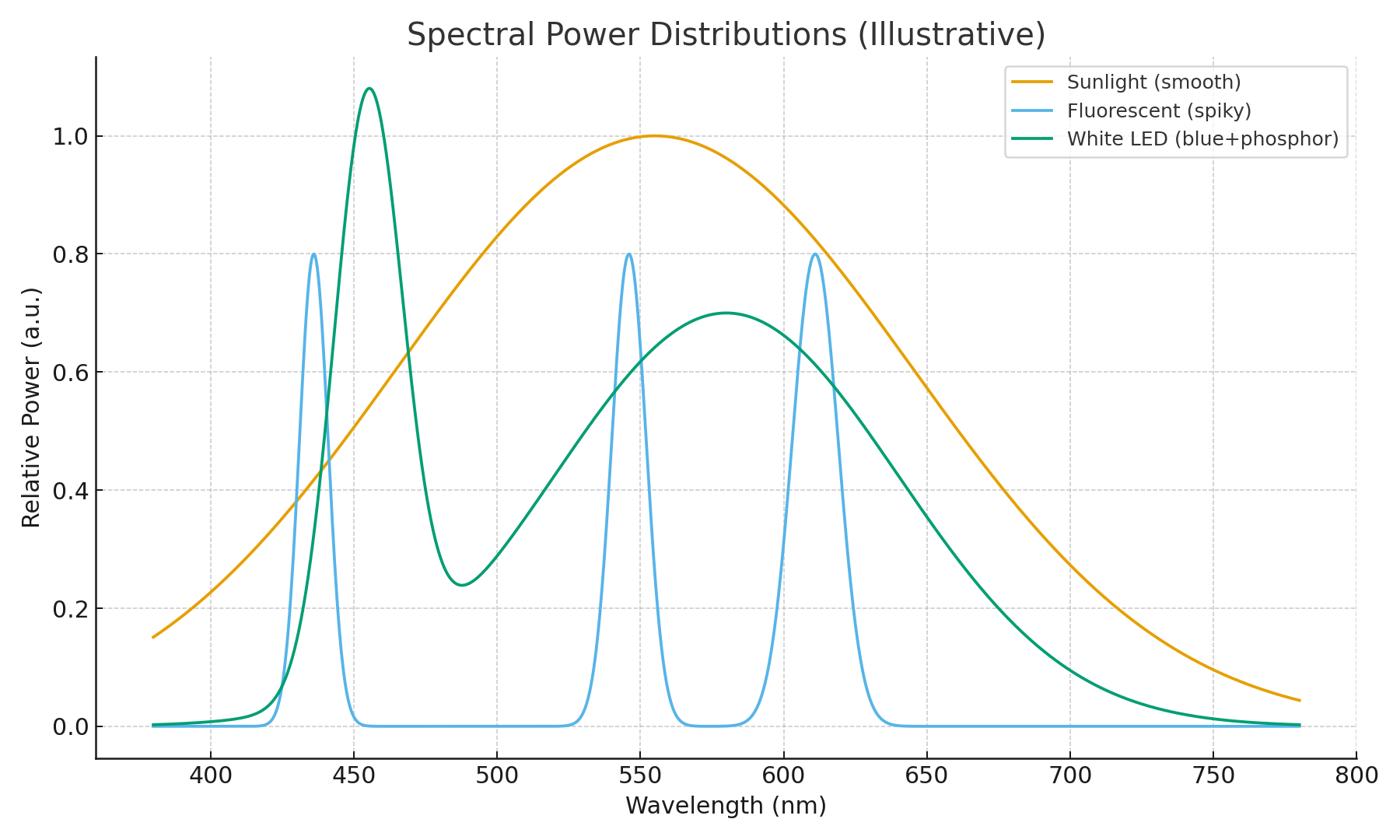
Spectral Power Distribution: The Fingerprint of Light
Every light source has its own spectral power distribution (SPD): how much energy it emits at each wavelength.
- Sunlight → smooth, broad spectrum.
- Fluorescent lamps → spiky, narrow peaks.
- White LEDs → sharp blue peak + broad yellow hump.
Units: watts per nanometer (W/nm), telling you how much power is packed into each tiny slice of the spectrum.
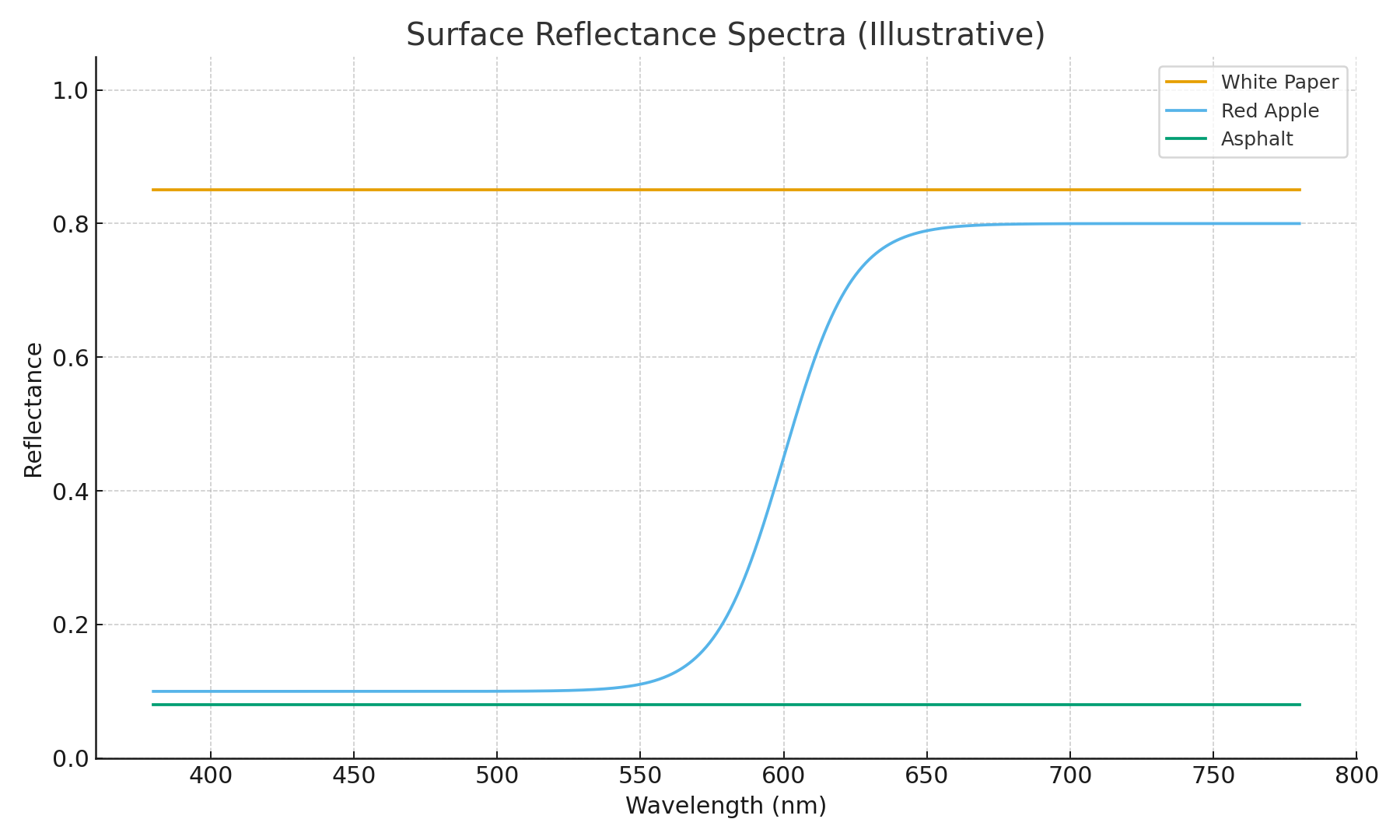
Surface Reflectance: How Materials Shape Light
Objects don’t emit light (unless they’re glowing); they reflect it. Reflectance is a ratio:
\[R(\lambda) = \frac{\text{Reflected power at }\lambda}{\text{Incident power at }\lambda}\]- White paper → flat, high reflectance across visible wavelengths.
- Red apple → high in red, low elsewhere.
- Asphalt → very low everywhere.
Camera Spectral Sensitivity: What Sensors Respond To
Cameras can’t sense wavelength directly — they need filters. A Bayer array puts red, green, and blue filters over the sensor. Each channel has its own spectral sensitivity curve: broad, overlapping ranges rather than neat slices.
So for a channel $c$:
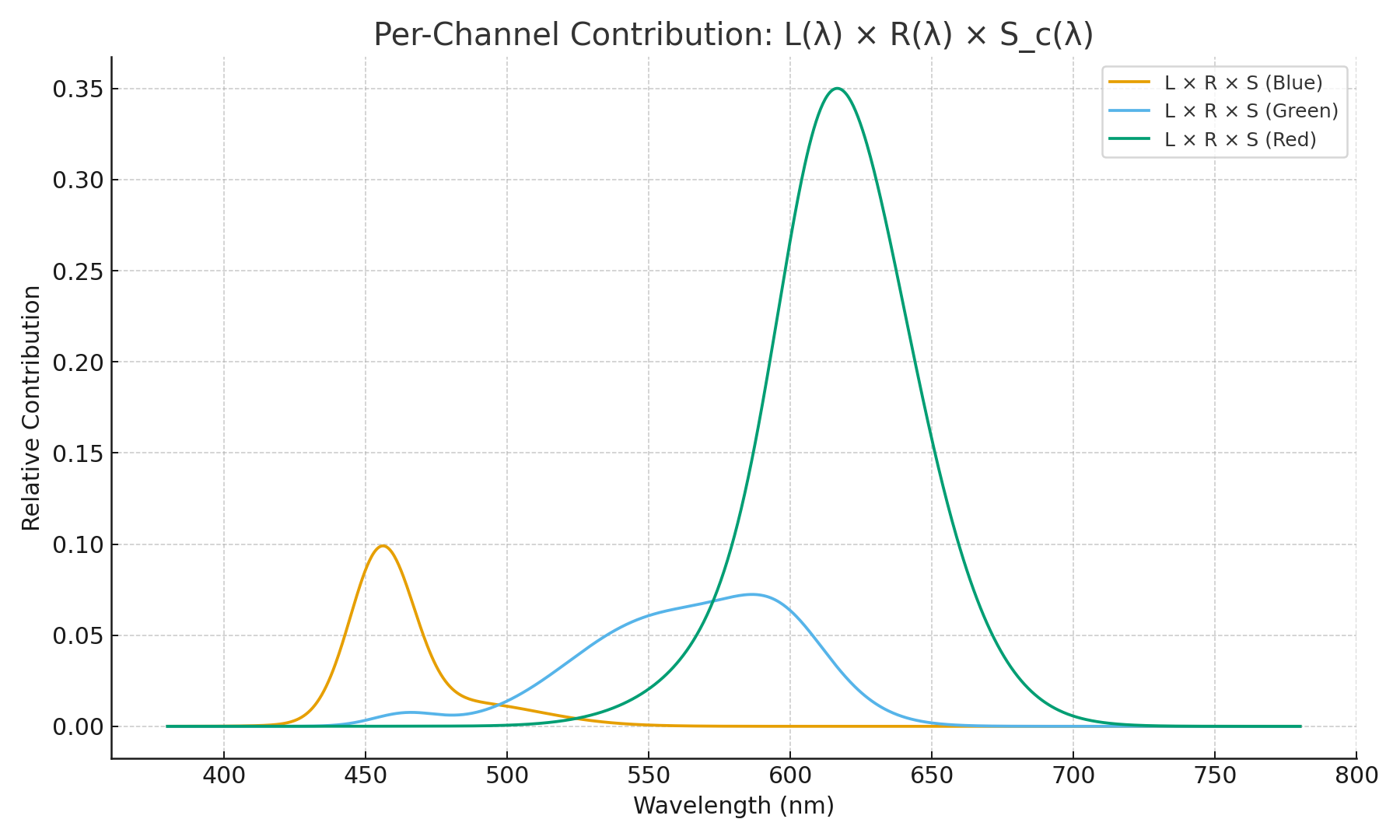
\[E_c = \int L(\lambda)\,R(\lambda)\,S_c(\lambda)\,d\lambda\]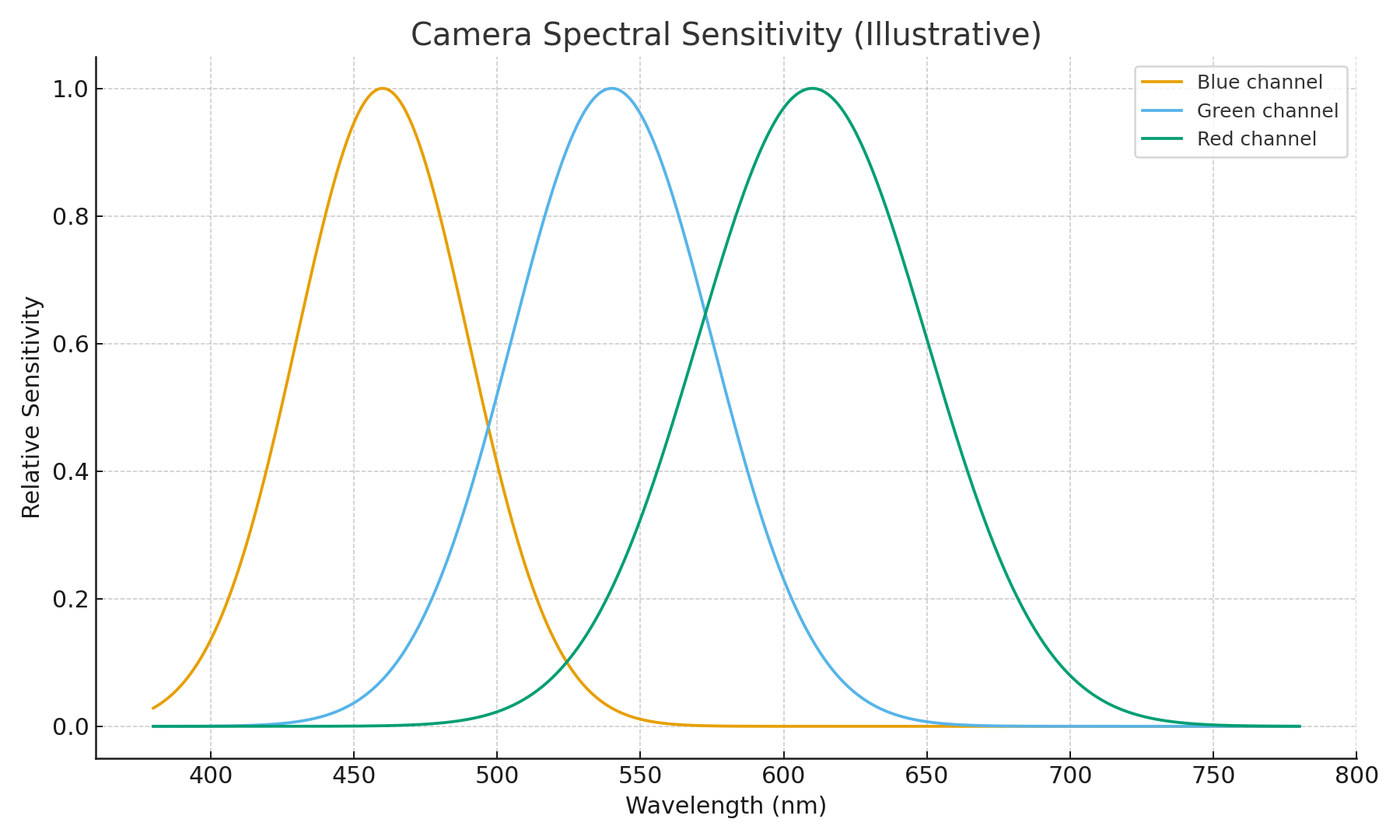
Why Multiplication?
Each stage scales the signal:
- The light source provides energy $L(\lambda)$.
- The surface keeps only a fraction $R(\lambda)$.
- The sensor responds with sensitivity $S_c(\lambda)$.
At each wavelength, multiply them. Then integrate over all wavelengths.
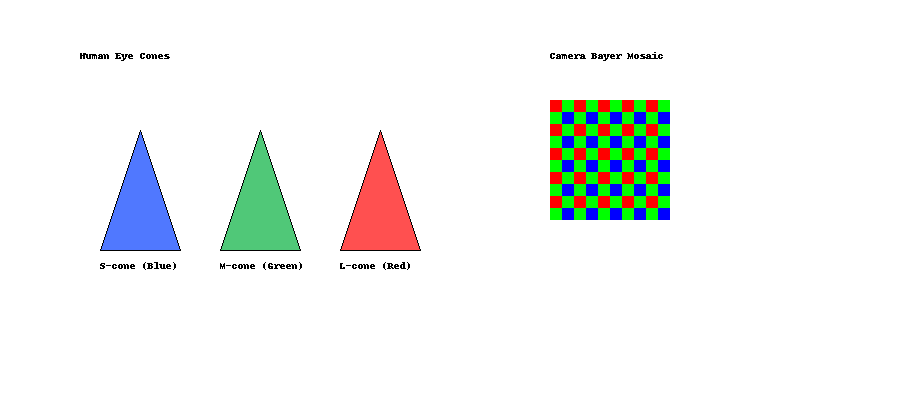
From Cones to Debayering
The human eye samples color with three cone types (S, M, L). Each has its own spectral sensitivity. The brain compares their relative outputs to reconstruct color.
A camera with a Bayer filter does something similar but clumsier: each pixel sees only one filter (R, G, or B), so it needs debayering (interpolating missing channels) to reconstruct full RGB.
Illuminant Estimation: Guessing the Light Source
From a single image, can we infer the color of the light source (the illuminant)?
Why it’s ill-posed:
- A white sheet under yellow light looks the same as a yellow sheet under white light.
- Camera gives only three numbers (R, G, B) per pixel, but both illuminant $L(\lambda)$ and reflectance $R(\lambda)$ are unknown.
[Diagram would show: Same image under different illuminants - white sheet under yellow light vs yellow sheet under white light]
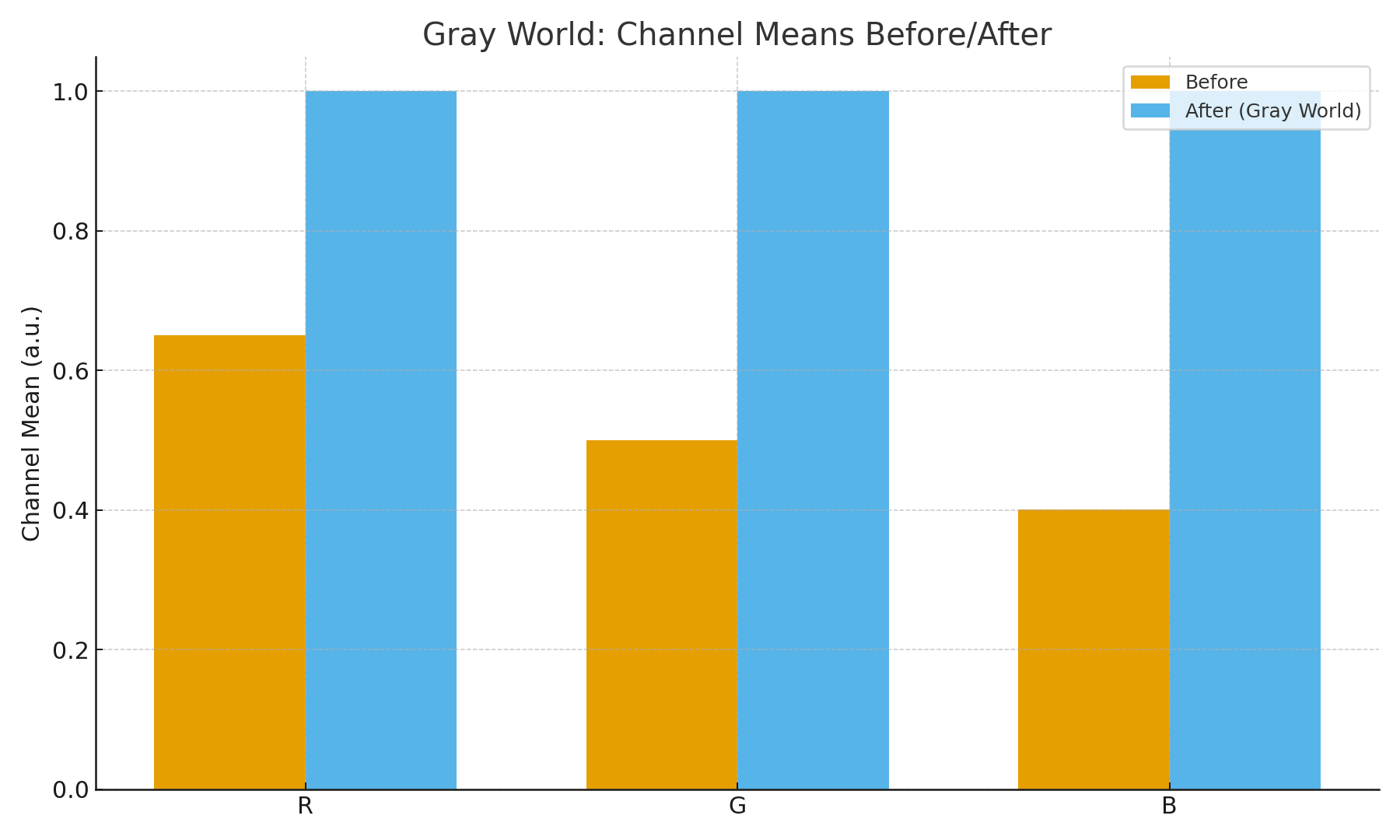
The Gray World Assumption
Classic trick: assume that, on average, the world is gray.
- Compute the mean of each channel across the image.
- If the averages aren’t equal, the imbalance is blamed on the illuminant.
- Correct by scaling channels to equalize the averages.
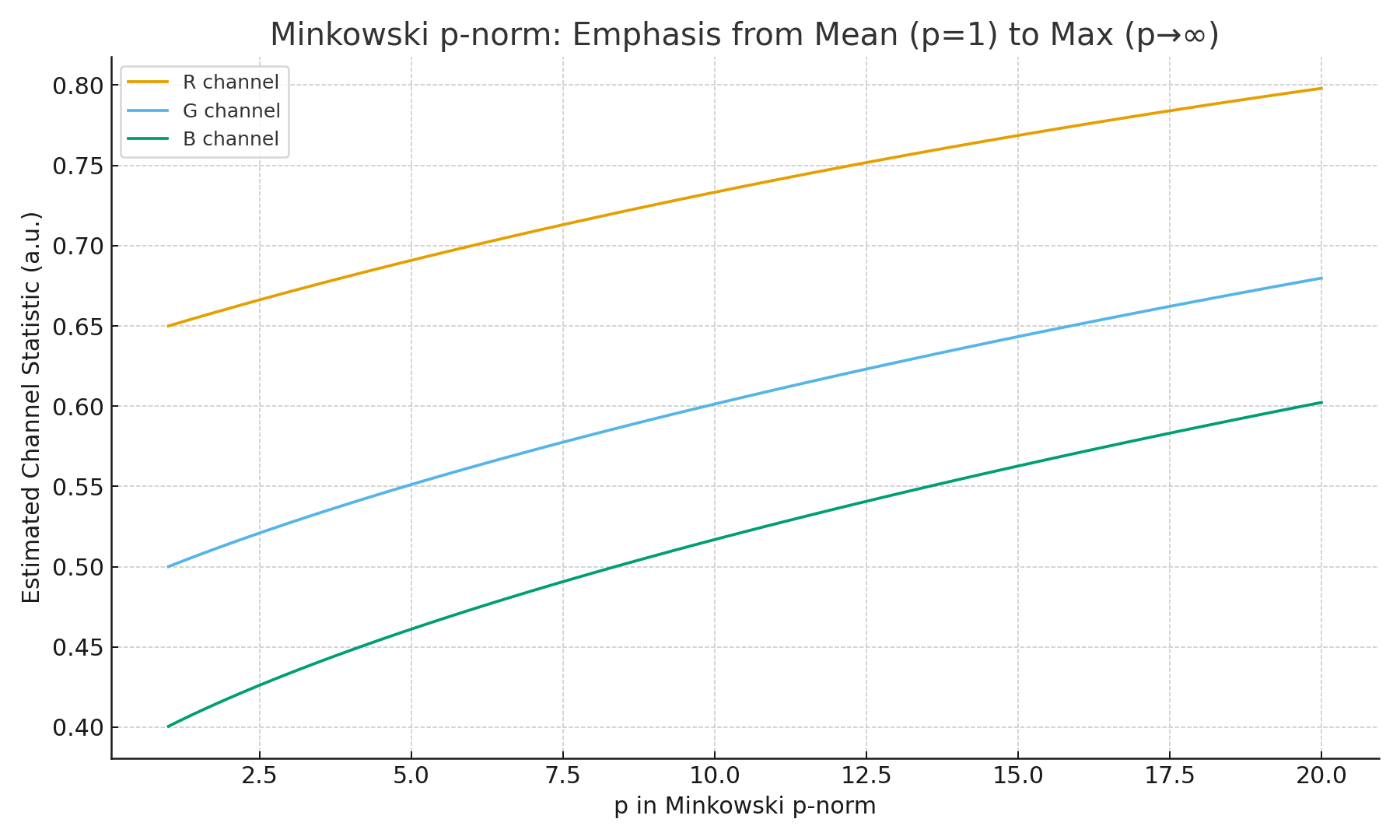
Minkowski Norm Estimates: A Family of Fixes
Generalize Gray World with the Minkowski $p$-norm:
\[E_c^{(p)} = \left(\frac{1}{N} \sum_i I_c(i)^p \right)^{1/p}\]- $p=1$: Gray World (average).
- $p=\infty$: White Patch (brightest pixel).
- Intermediate $p$: Shades of Gray methods.
Coping with Limitations
Researchers improved on Gray World:
- Smarter stats: Gray-Edge, Shades-of-Gray.
- Region-based: local estimates, then merging.
- World priors: daylight color curves, known object colors.
- Learning-based: CNNs, transformers, illuminant maps.
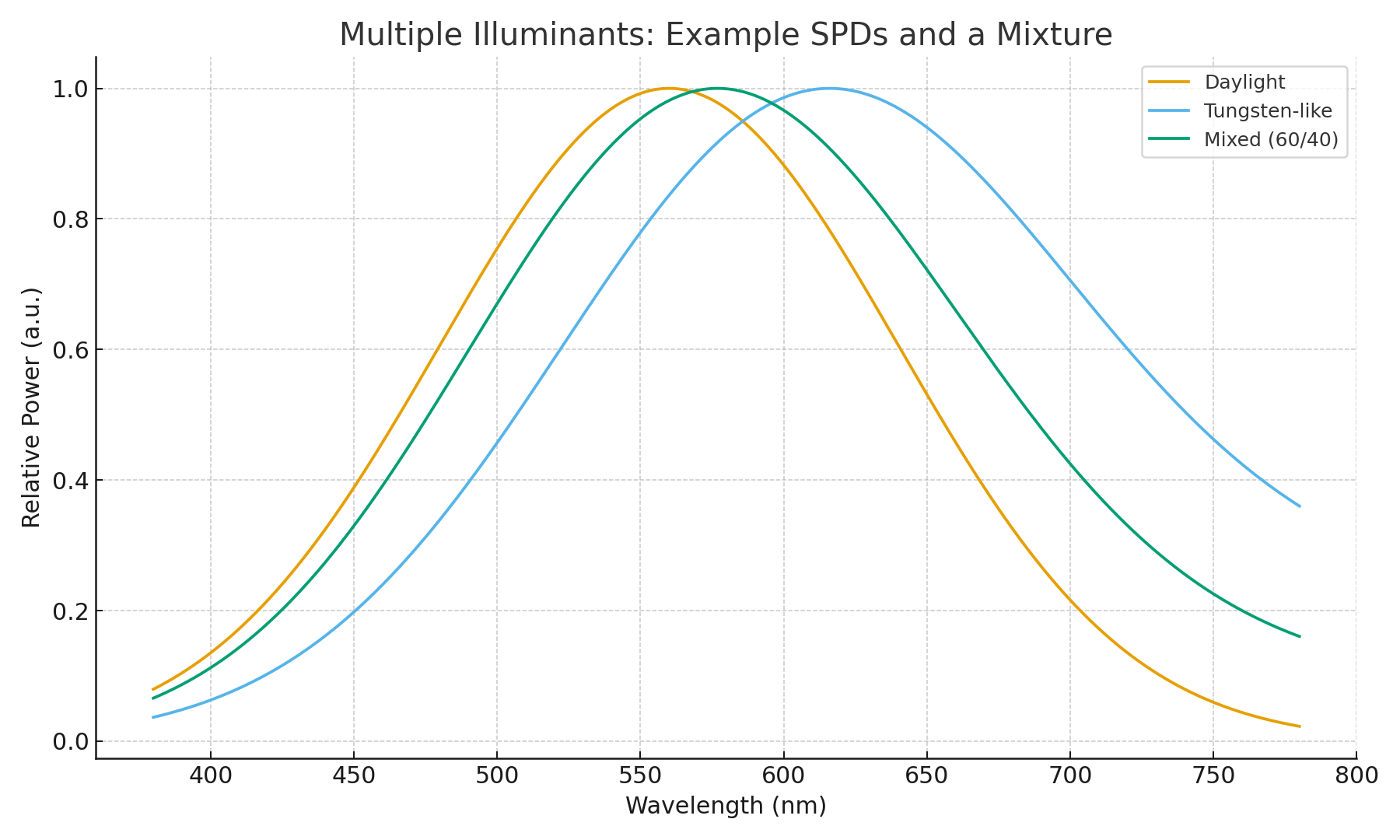
Multiple Illuminants: The Real Mess
Life rarely has one light source. A window and a lamp, fluorescent tubes and skylight — every pixel becomes a blend of multiple SPDs.
Computer vision strategies:
- Local estimation per region.
- Use edges, shadows, specular highlights.
- Train deep models to output illuminant fields.
- Sometimes, ask the user (click the white patch in software).
How Humans Do It: The Goal of Color Constancy
What we’re trying to achieve: See a red apple as red whether it’s under yellow candlelight, blue skylight, or white fluorescent tubes. This is called color constancy — the ability to perceive object colors as stable despite dramatic changes in illumination.
Why This Matters
Without color constancy, our visual world would be chaos:
- A banana would look yellow at noon, orange at sunset, and blue-green under fluorescent light
- We couldn’t recognize objects by color across different lighting conditions
- Survival tasks (ripe fruit, healthy skin, dangerous signals) would be impossible
The Human Advantage
Cameras struggle with this because they’re largely context-blind. A white balance algorithm sees RGB numbers and applies math. Humans use contextual intelligence that evolved over millions of years.
How Our Brains Cheat Elegantly
1. Local Adaptation
Different parts of your retina recalibrate independently:
- Look at a lamp, then at a daylight window — your eye adapts the sensitivity of different retinal regions
- This lets you see both the warm lamp-lit area and cool daylight area as having “normal” colors simultaneously
- Cameras can’t do this — they apply one global white balance to the entire image
2. Contextual Priors
Your brain has a database of “known” object colors:
- Snow is white, grass is green, skin has predictable tones
- When your brain sees something that should be white but looks yellowish, it assumes yellow lighting and mentally “corrects” the entire scene
- This is why the famous blue/black vs white/gold dress illusion works — people make different assumptions about the lighting
3. Attention-Driven Tuning
Your focal attention actively shifts color balance:
- Fixating on the lamp-lit part of a scene makes that region look more neutral
- Look at the daylight area, and suddenly that looks normal while the lamp area looks warm
- This is like having a smart, adaptive white balance that follows your gaze
4. Specular Highlights
Shiny surfaces give away the true illuminant color:
- The bright reflection off a glossy apple shows the actual light color
- Your brain uses these “uncorrupted” signals to infer what the lighting really is
- Then it mentally subtracts that color cast from everything else
5. Edge and Shadow Analysis
Humans are incredibly good at using spatial relationships:
- Cast shadows reveal the light source color
- Color changes at edges between lit and shadowed areas
- The same surface under different illumination zones gives multiple data points
The Remarkable Result
Put it all together, and humans achieve something cameras still struggle with: seeing object color, not illuminant color. We literally see past the physics to perceive the underlying material properties.

What Makes This Image Special
This image demonstrates the most important principle in human color perception: identical pixels can look completely different depending on context.
The Illusion Breakdown:
- Left side: Cool blue-tinted environment (simulating daylight/shade)
- Right side: Warm red-tinted environment (simulating incandescent/sunset light)
- Gray patches: Physically identical RGB values in both squares
What You Actually See:
- Left gray patch: Appears warmer, more orange/yellow
- Right gray patch: Appears cooler, more blue/purple
- Your brain: Automatically “corrects” for the surrounding illumination
Why This Happens (The Mechanisms in Action):
1. Contextual Priors: Your brain assumes the gray patches are supposed to be neutral. When it sees a “neutral” patch in blue light, it thinks: “This should be gray, but it looks bluish, so the lighting must be blue. Let me mentally subtract blue to recover the true gray color.”
2. Local Adaptation: The left and right halves of your retina adapt to different color environments simultaneously. The blue-adapted left region becomes less sensitive to blue, making the gray patch look more orange by contrast.
3. Simultaneous Contrast: The surrounding colors directly influence perception. Blue surroundings make the center appear more orange; red surroundings make it appear more blue.
4. Spatial Intelligence: Your brain uses the color gradient from edge to center to infer lighting conditions and automatically compensate.
The Profound Implication:
This is exactly what happens in real-world color constancy. When you look at a white piece of paper under yellow candlelight, your brain:
- Sees yellowish pixels
- Recognizes contextual cues (warm light source, evening setting)
- Assumes the paper “should” be white
- Mentally subtracts the yellow cast
- Makes you perceive the paper as white
Why Cameras Fail Here:
A camera analyzing this image would report:
- “Left patch: RGB(128,128,128)”
- “Right patch: RGB(128,128,128)”
- “Conclusion: Identical colors”
The camera is technically correct but perceptually wrong. It lacks the contextual intelligence to understand that identical pixels in different illumination contexts represent different material properties.
The Research Challenge:
Building algorithms that can do what your brain just did effortlessly:
- Detect illumination context from spatial patterns
- Infer material properties separate from lighting
- Apply appropriate contextual corrections
- Handle multiple simultaneous lighting conditions
This single image encapsulates why computational color constancy is one of computer vision’s most challenging problems — we’re trying to reverse-engineer millions of years of visual evolution.
Why Cameras Can’t Match This (Yet)
Cameras lack:
- Contextual memory: They don’t know what color grass “should” be
- Spatial intelligence: They can’t reason about shadows, highlights, and material boundaries
- Attentional control: They can’t adaptively focus processing on relevant regions
- Temporal integration: They can’t combine information across eye movements and time
The goal for computational color constancy: Build algorithms that can do even a fraction of what human vision accomplishes effortlessly every day.
Closing Thoughts
From physics to perception, the chain is the same:
\[\text{Pixel value} = L(\lambda) \times R(\lambda) \times S(\lambda)\]The real trick is separating them. Cameras rely on algorithms; humans rely on context and adaptation. Neither is perfect, but both are ingenious.